
PixInsight 最好玩的地方不是图像处理,而是跑分[doge]。
注:本文内容仅供参考,每台电脑的硬件配置和软件环境均不一样,如因遵循本文而造成你电脑出现任何问题,本人盖不负责 🙂
前言
跟其他专业图像处理软件相比较,PixInsight 更能吃电脑资源,甚至可以说你有多少它就能吃多少,在特定的处理任务之下,常见的 HEDT 配置都能被 PI 吃满。这并不是说 PI 的效率不高,而是跟深空图像后期的特点有关:大量文件同步校准、对齐、叠加,16bit、32bit 甚至 64bit 图像文件的修改,甚至还有专门玩超大型马赛克拼接、听到有几亿像素的主亮场就兴奋的赛博疯子。遇到这些情况,一般电脑玩家的电脑自然叫苦不迭。
想追求更快的处理速度,最好最快的方法肯定就是充钱升级。CPU超频、内存超频也不错,我曾经花过几天来研究和折腾,提升幅度也是可见的。但如果不考虑硬件升级和超频,只从软件方面着手优化PI 和环境配置,电脑跑 PI 能更快吗?
答案是可以的。
PI 的操作可以大致分为两个类型:预处理和后期处理。在预处理阶段(校准、对齐、叠加), PI 需要对大量文件进行处理然后生成新的文件,这时候 PI 主要吃处理器的多核能力和内存容量;而后期处理(反卷积、拉伸、锐化、降噪等)则更吃处理器的单核能力和 Swap 交换分区传输速度。如果想知道 PI 在自己电脑下的处理能力,最简单而有效的方法是使用 PI 自带的官方跑分脚本( Script – Benchmarks – PixInsight Benchmark)。打开脚本然后点击 Run Benchmark 就可以安心等待结果了。
官方的跑分程序会下载一组素材,进行预处理和后期处理,再根据处理时长来计算 CPU 得分和 Swap 得分,最后结合两者分数计算出一个总得分。在一定程度上(鸭哥的电脑除外),这个跑分可以客观地看作你电脑跑 PI 性能的指标。
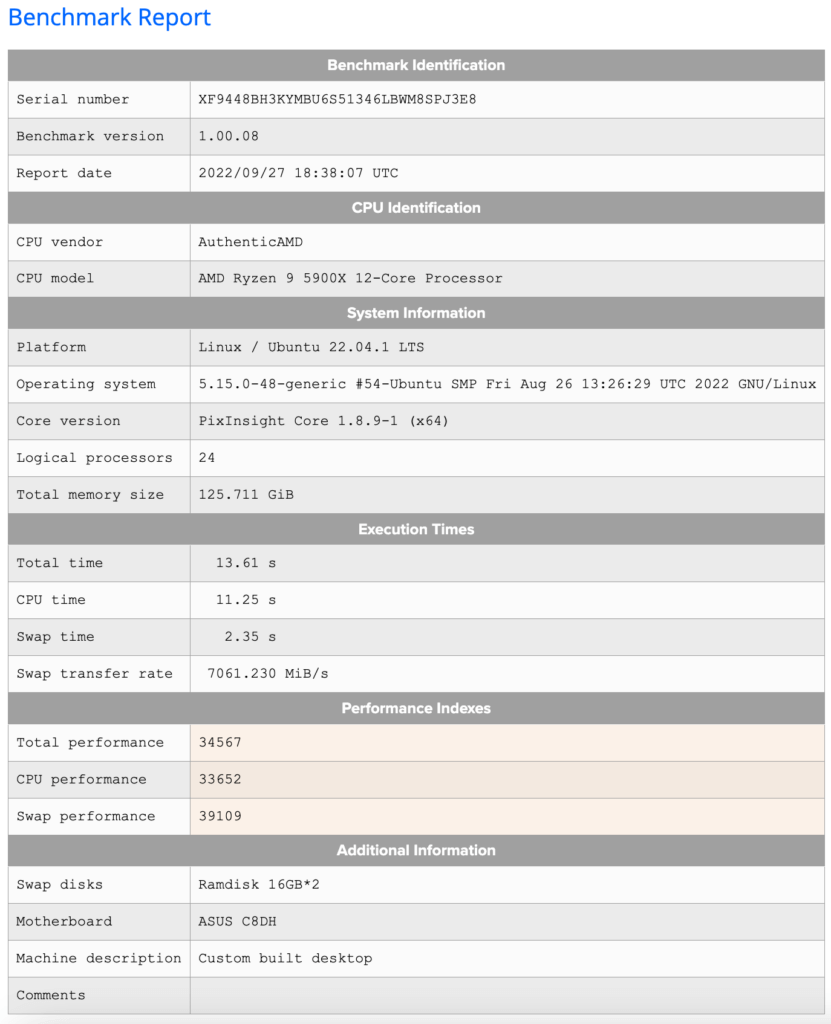
你可以将特定跑分结果上传到 PI 官网,然后在数据库中和其他用家上传的得分进行对比。
在实操中,我们大致可从以下三方面着手优化:
- 更换操作系统
- 调整SWAP 交换分区文件夹
- 启用显卡 CUDA 加速
更换操作系统
具体来说,是将操作系统更换为 PI 的亲儿子, Linux 系统。用 MacOS 的可以忽略这节内容了。
根据官方 FAQ,PI 是在 Red Hat Enterprise Linux Workstation 7.4 下以 C++ 语言开发的,然后再以 Linux 版本为基础移植到 Windows、Mac 和 FreeBSD 平台。开发组指出, Linux 版本的 PI 最稳定、功能最丰富(?),通常来说也能发挥最好的性能。
以我自己的硬件平台(AMD 5900x + 128GB DDR4 3200)测试出来的结果来看,在 Ubuntu 22.04 下,CPU 的得分会比 Windows 11 Pro 下高出约 15%。你也可以在官方跑分数据库中可以看出, Linux 平台的 CPU 得分一般都会比 Windows 高,无论用的是 Intel 还是 AMD。
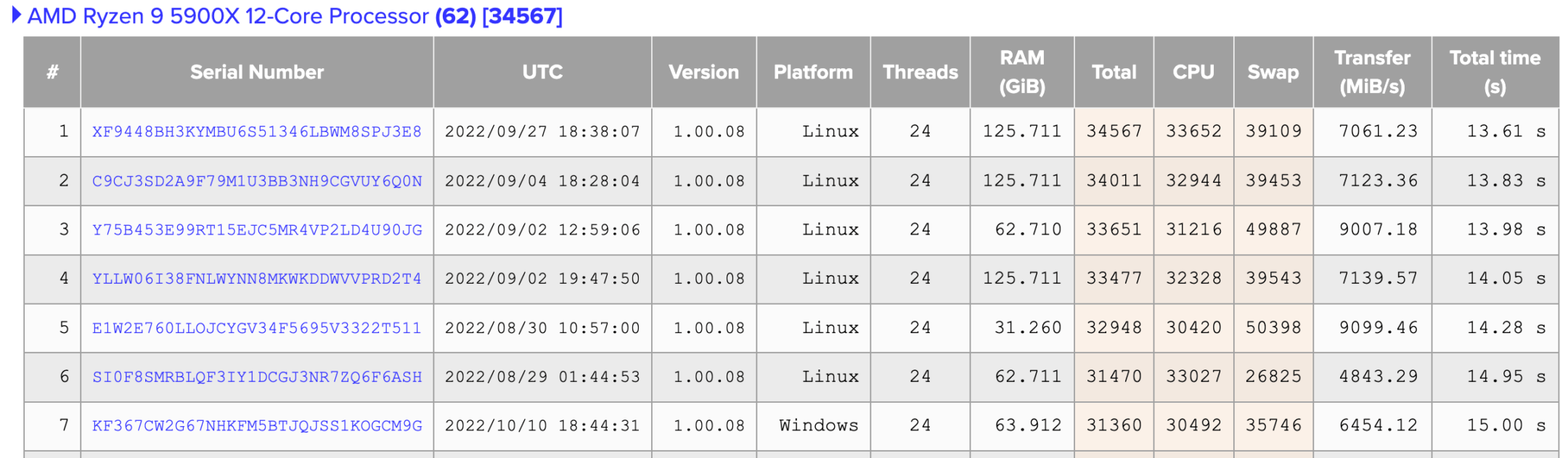
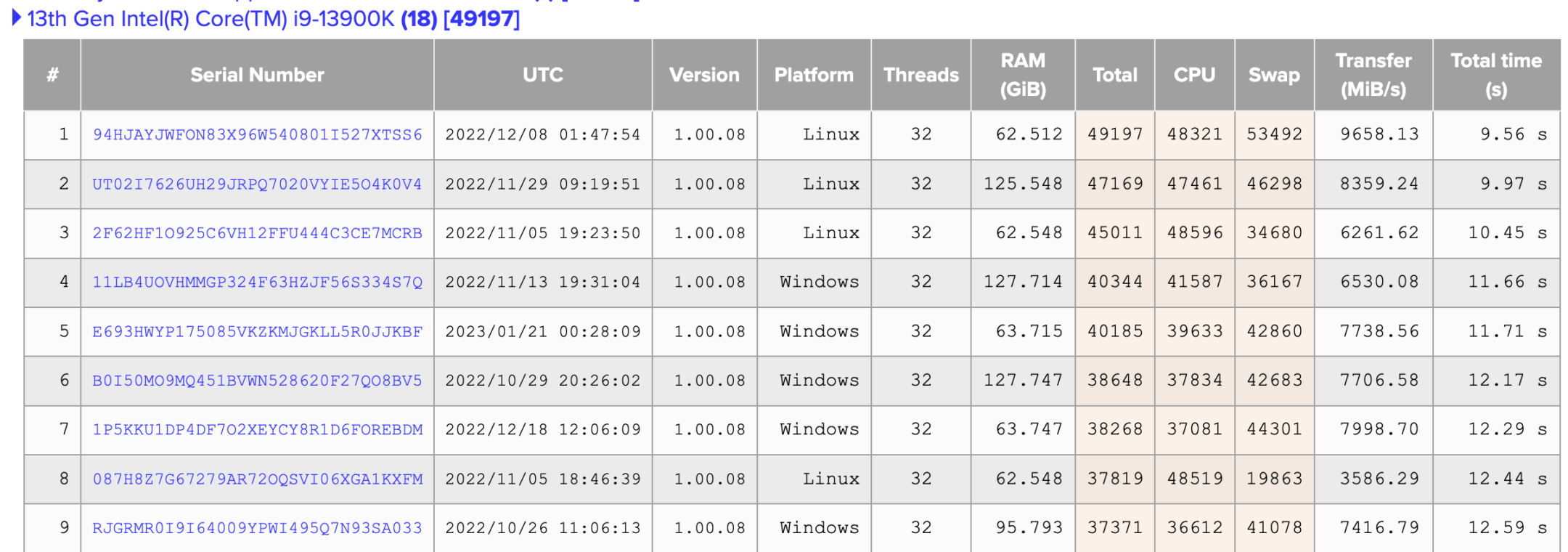
知识所限,我无法得知这个差距到底是“PI 原生 vs 移植”还是由“Linux vs Windows”哪个原因带来的,但是 PI 的 CPU 处理性能在这两个系统下确实有普遍的、显著的差别。
别看这只有 10% 到 20% 的差距,如果是处理大型素材,确实能省不少时间。我以前在 Windows 下遇到的闪退等问题,在 Linux 版本下也不复存在。
况且,你不用花一分钱就能享受这个10% CPU 性能的提升 :)
当然,Linux 系统有一定的使用门槛,加上很多我们日常使用的软件都没有 Linux 版本,因此普通用家全面更换到 Linux 肯定是不现实的。以我为例,我是安装了双系统,处理图片的时候用 Kubuntu,打游戏日常使用的时候就用 Win。
啊对了,还有一个换到 Linux 的理由:根据我的印象经验,另一个常用的深空图像处理软件 Astro Pixel Processor 的 Linux 版也比 Windows 版快……好像是。
调整 Swap 交换分区文件夹
OK,如果换 Linux 不现实的话,那么“调整 PI 的 Swap 交换分区文件夹”这个操作,在所有平台上都能用,而且优化效果显著。此方法的唯一限制是,如果你只使用 HDD 机械硬盘而不是 SSD 或 Ramdisk,那可能无法带来性能上的提升。
首先我们来认识一下 PI 的 Swap 交换分区的运行原理。
Swap 本来是 Linux 系统特有的名称,你可以理解为 PS 里面的缓存文件夹。从 PI 打开一张图片后,对这张图片进行修改(裁切、拉伸、锐化、降噪等操作)之后,PI 会在 Swap 文件夹中写入一次进行保存。这张图像被修改多少次,PI 就会在 Swap 写多少次。当你执行 undo 操作的时候,PI 就会读取 Swap 文件夹里面的缓存文件。因此,这个 Swap 文件夹的读写速度,对 PI 的总体运行速度有很关键的影响。你处理的图像体积越大,这个影响就越明显。
而 PI 的 Swap 系统有一个关键的特性:如果你设置数量为 n 的 Swap 文件夹,那么 PI 在写入文件缓存时会先将单个文件切割为 n 个分块,然后再同时将这些分块分别写入各个 Swap 文件夹。 undo 的时候,PI 也会同时从各个 Swap 文件夹中读取所有分块。这个可以看作 Swap 读写的“多线程”特性。
目前主流的 PCIE 4.0×4 Nvme 固态硬盘在利用 PI 这个特性的情况下,都可以跑满理论上的读写带宽。例如我的西数 sn850 2T 固态,在 PI 下 Swap 就能跑到超过 5000MB/s 的理论写入速度。
但是问题来了,PI 的默认设置只有一个 Swap 文件夹!
如果不去主动修改,我电脑在 PI 下“单线程”的 Swap 读写大约只有 1500MB/s,还不到理想跑分的1/3!
所以啊,这个优化操作对固态硬盘来说就非常必要了。
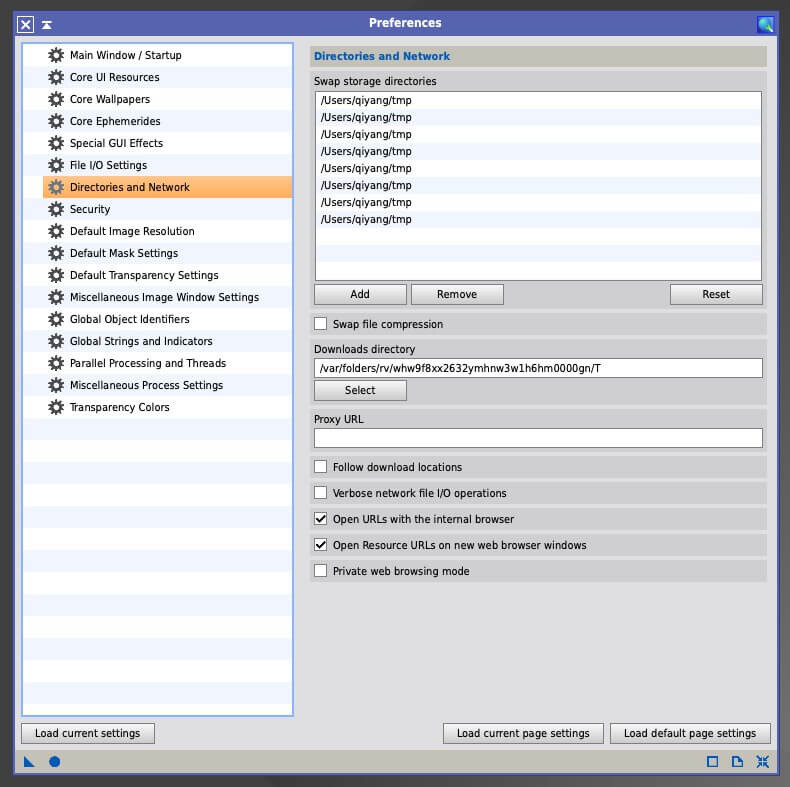
设置的方法也不复杂:点击 Edit 菜单,点击 Global Preferences,点选 Directories and Network,点击 Add 添加新的 Swap 文件夹。记得点击左下角的圆形保存设置,然后重启 PI 才算正式生效。
你可以添加同一个文件夹作为 Swap 文件夹,也可以添加不同的文件夹,甚至还可以添加 Ramdisk 文件夹。
那么问题又来了:应该添加多少个 Swap 文件夹呢?
这里其实没有标准答案,因为每台电脑的配置不同,不能一概而论。如果是用固态硬盘,那么我推荐的调试方法是:
- 设置 4 个 Swap,用 PixInsight Benchmark 跑5次分,计算平均 Swap 分数;
- 设置 6 个 Swap,用 PixInsight Benchmark 跑5次分,计算平均 Swap 分数;
- 设置 8 个 Swap,用 PixInsight Benchmark 跑5次分,计算平均 Swap 分数;
- 如此循环反复到大概 24 个 Swap,找到最高的 Swap 分数,然后用回最高分的设置。
如果用的是传统机械硬盘,那么可能只需要设置两个 Swap 就够了,原因是机械硬盘基本上没有多路同时读写的能力。
除此之外,Global Preferences 内的 Parallel Processing and Threads 标签页里还有一个关于多线程读写的设置: Maximum number of file reading / writing threads。为什么这里又有一个控制文件多线程读写的设置呢?
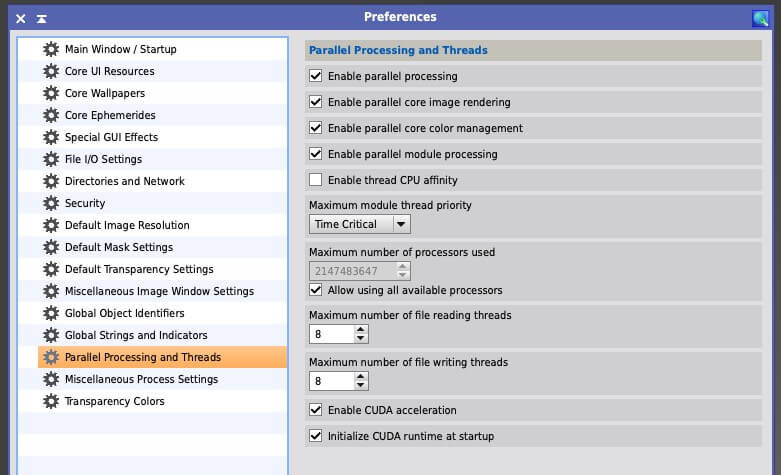
这就很让人迷惑了。既然你 PI 默认就开 8 个多线程文件读写,为什么又默认只有 1 个 Swap 文件夹呢?或许是要照顾还在用机械硬盘的用户?
不过无论怎样都好,这个设置的调整同样会影响整体 Swap 读写速度。我的建议也是一样的,多调整几次,记录下最高得分,然后使用那个设置。
最后说说要不要设置 Ramdisk 作为 Swap。Ramdisk 是在内存划分出一部分空间作为虚拟文件夹,DDR 4 内存的传输带宽会比传统的机械硬盘和 Sata 固态快十数倍,然而跟目前主流的 PCIE 4.0 Nvme 固态动辄 5000 甚至 7000MB/s 相比优势不算大,而且还会占用稀缺的内存容量。因此,只有在你拥有大容量内存和使用非 PCIE 4.0 固态的情况下,设置 Ramdisk Swap 才有实际意义。
启用显卡 CUDA 加速
换 Linux 系统能带来约 10% 的 CPU 得分提升,优化 Swap 能带来三四倍的 Swap 得分提升,那么启用显卡的 CUDA 加速则可以为某些操作带来最多十倍的提升。
想要获得这个性能提升,必须同时符合以下三个条件:
- 使用 Nvidia GTX 9 系列或更新的显卡,而且支持 CUDA 核心加速;
- 使用 Windows 或者 Linux 操作系统;
- 在 PI 使用 Starnet、Starnet2、StarXTerminator、NoiseXTerminator 和 BlurXTerminator 等操作。
Windows 下的启用方法,教主在南方天文的微信号上已经讲得非常清晰和详细了,这里无需重复,感兴趣的可以点击这里学习:提速9倍!用显卡给你的PixInsight加速吧!
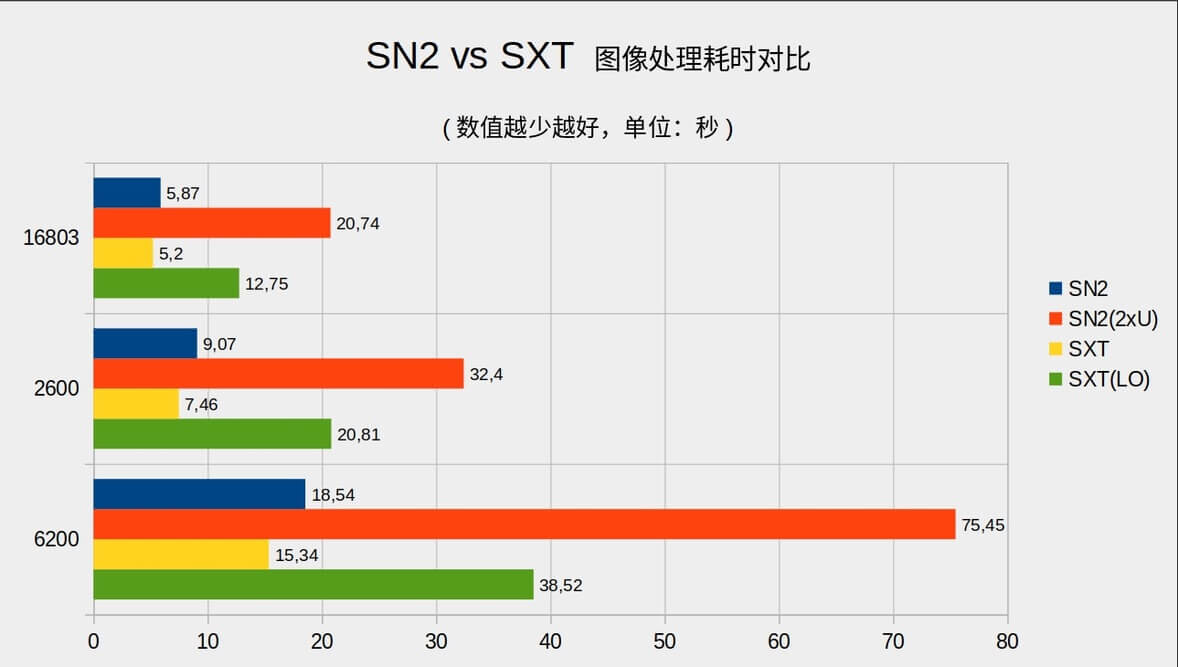
这是我电脑启用了显卡 CUDA 加速后,SXT 和 Starnet2 处理图片的速度。显卡是 RTX 3090。
而 Linux 系统下启用显卡 CUDA 加速的方法则稍微有点不同。我之前折腾了两三个晚上,幸好终于给我捣鼓成功。具体方法如下:
1, 安装 CUDA & cudnn
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin
$ sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
$ wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda-repo-ubuntu2204-11-8-local_11.8.0-520.61.05-1_amd64.deb
$ sudo dpkg -i cuda-repo-ubuntu2204-11-8-local_11.8.0-520.61.05-1_amd64.deb
$ sudo cp /var/cuda-repo-ubuntu2204-11-8-local/cuda-*-keyring.gpg /usr/share/keyrings/
$ sudo apt-get update
$ sudo apt-get -y install cuda
$ sudo apt install libcudnn8
Done.
2, 安装 libtensorflow-gpu
先下载 libtensorflow-gpu-linux-x86_64-2.6.0.tar.gz
$ sudo tar -C /usr/local -xzf libtensorflow-gpu-linux-x86_64-2.6.0.tar.gz
$ sudo ldconfig /usr/local/lib
转到文件夹 /opt/PixInsight/bin/lib
$ sudo mkdir /opt/temp
$ mv libtensorflow* /opt/temp
$ export TF_FORCE_GPU_ALLOW_GROWTH="true"
Done.
PS: Linux 下安装 StarnetV2 的方法(不这样安装的话 PI 会找不到插件)
$ sudo chown root:root StarNet2-pxm.so
$ sudo chmod 775 StarNet2-pxm.so
$ sudo chown root:root StarNet2_weights.pb
$ sudo chmod 775 StarNet2_weights.pb
$ sudo mv StarNet2-pxm.so /opt/PixInsight/bin
$ sudo mv StarNet2_weights.pb /opt/PixInsight/bin
打开 PixInsight: Process menu -> Modules -> Install Modules
点击 "Search",看到 Starnet 2 出现,然后点击 "Install"
Done.End.
太卡啦
优化了一下 🙂 现在应该好点了。
踩踩
踩你老板
教主那篇文章是不是有一个小笔误来着
是吗?我好像没看出来。。。
我换了192线程的霄龙9654,CPU不能完全调用,只有1,3W分,尝试了各种设置,是不是在win11下,PI不能调用这么多线程?
教主的网盘文件已消失,相关文件下载:
https://developer.nvidia.com/cuda-toolkit-archive
https://developer.nvidia.com/rdp/cudnn-archive
https://www.tensorflow.org/install/lang_c?hl=zh-cn